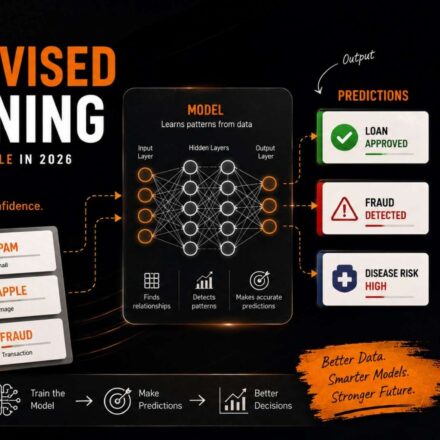
Introduction
Supervised Learning is one of the most important concepts in modern artificial intelligence (AI). Today, many of the smart technologies we use every day rely on supervised learning to make accurate predictions and informed decisions.
From email spam detection to product recommendations and medical diagnosis systems, supervised learning plays a major role behind the scenes. As a result, it has become the foundation of many machine learning applications.
In simple terms, supervised learning teaches computers how to learn from examples. Instead of manually programming every rule, developers provide data with known answers. Consequently, the machine learns patterns and uses those patterns to make future predictions.
Furthermore, supervised learning is often the first machine learning technique beginners learn because it is easier to understand than many advanced AI concepts. Therefore, if you want to build a strong foundation in machine learning, learning supervised learning is an excellent starting point.
In this beginner-friendly guide, you will learn what supervised learning is, why it matters, how it works, its key concepts, common algorithms, and its real-world applications.
Read More: Machine Learning: The Ultimate Guide for 2026
What Is Supervised Learning?
Supervised Learning is a machine learning approach where a model learns from labeled data. In other words, every training example contains both the input and the correct output.
The model studies these examples and learns the relationship between them. Afterwards, it uses that knowledge to predict outputs for new, unseen data.
For example, imagine you want to teach a computer to recognize cats and dogs. You provide thousands of images labeled as either “cat” or “dog.” As a result, the system gradually learns the visual differences between the two animals.
Eventually, when a new image appears, the model can predict whether it contains a cat or a dog.
Understanding Labeled Data
Labeled data contains two parts:
| Component | Description | Example |
|---|---|---|
| Input | Information given to the model | Customer age, salary |
| Output | Correct answer associated with input | Will buy product or not |
For instance:
| Input (Email Content) | Output Label |
|---|---|
| “Win a free vacation now!” | Spam |
| “Meeting scheduled for tomorrow” | Not Spam |
Because the answers are already known, the algorithm receives guidance during training. Therefore, the learning process becomes more structured and accurate.
Read More: Supervised Learning in 2026: Best Methods, Models, and Uses
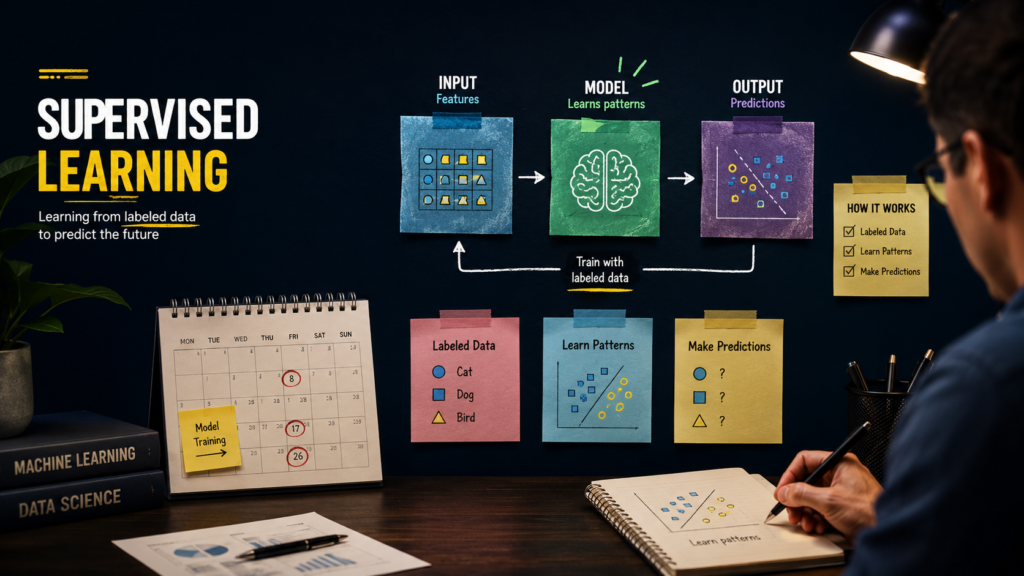
Input-Output Pairs Explained
Every supervised learning dataset consists of input-output pairs.
Input → Output
- House features → House price
- Medical symptoms → Disease prediction
- Student scores → Final grade
- Customer activity → Purchase prediction
Consequently, the algorithm learns to map inputs to outputs with increasing accuracy.
Why Supervised Learning Matters
Supervised learning has transformed how organizations make decisions and automate tasks. Today, businesses use it to solve problems that would otherwise require significant human effort.
Furthermore, supervised learning allows machines to process huge amounts of data quickly. As a result, companies can improve efficiency, reduce costs, and deliver better customer experiences.
Automation Across Industries
Many industries depend heavily on supervised learning.
Read More: What Is Supervised Learning? Definition, How It Works, and Common Examples
Healthcare
Doctors use supervised learning models to identify diseases from medical images and patient records.
Consequently, medical professionals can detect health conditions earlier and make faster decisions.
Finance
Banks use supervised learning to detect fraudulent transactions.
Furthermore, these systems can analyze millions of transactions in real time and flag suspicious activities immediately.
Retail
Online stores use supervised learning to predict customer behavior.
As a result, companies can recommend products more accurately and increase sales.
Education
Educational platforms analyze student performance using supervised learning.
Therefore, teachers can identify struggling students and provide targeted support.
Transportation
Self-driving vehicle systems use supervised learning to recognize road signs, pedestrians, and other vehicles.
Consequently, transportation technology becomes safer and more reliable.
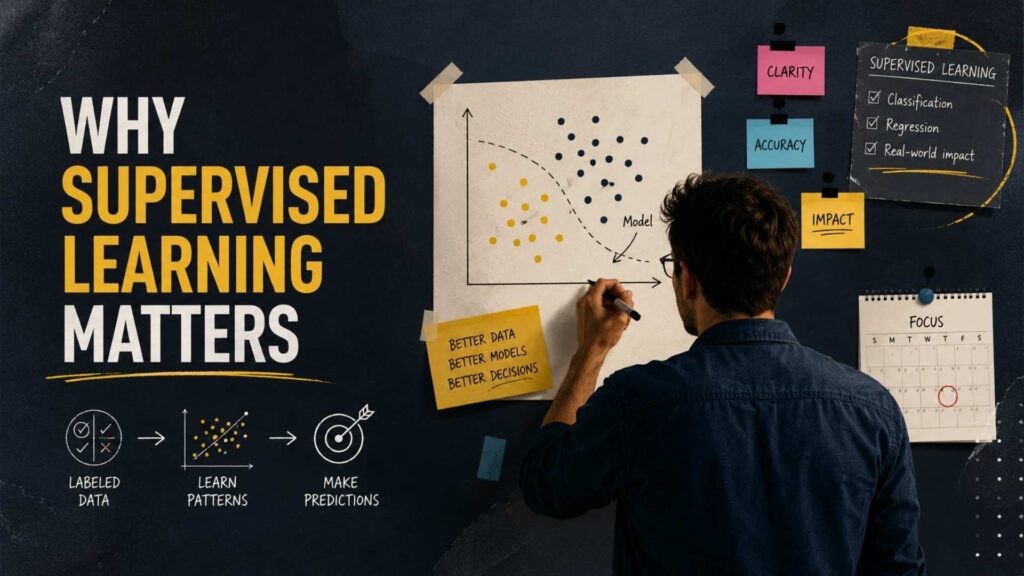
How Supervised Learning Works
Understanding the workflow of supervised learning is essential for beginners.
Although the underlying mathematics can be complex, the overall process is surprisingly straightforward.
The process generally consists of three major stages:
- Data Collection
- Training Phase
- Testing Phase
Step 1: Collecting Training Data
The first step is gathering labeled data.
This dataset serves as the learning material for the model. Therefore, the quality of the dataset directly affects model performance.
For example:
| House Size | Bedrooms | Price |
|---|---|---|
| 1200 sq ft | 2 | $150,000 |
| 1800 sq ft | 3 | $250,000 |
| 2500 sq ft | 4 | $400,000 |
The model studies these examples and looks for patterns.
Read More: Supervised Learning: What It Is, How It Works, and Practical Use Cases
Step 2: Training Phase
During training, the algorithm processes the labeled data.
It compares its predictions against the correct answers and measures the difference between them.
If the predictions are inaccurate, the model adjusts its internal parameters.
Moreover, this process repeats many times.
Consequently, prediction accuracy gradually improves.
The Role of Ground Truth
Ground truth refers to the correct answers contained in the dataset.
For example:
| Image | Ground Truth Label |
|---|---|
| Dog Image | Dog |
| Cat Image | Cat |
| Bird Image | Bird |
The algorithm uses these correct labels as references.
Therefore, it knows whether its predictions are right or wrong.
Without ground truth, supervised learning would not be possible.
Step 3: Testing Phase
After training, the model is evaluated using new data that it has never seen before.
This stage determines whether the model can generalize its learning.
For instance, if a model was trained on 10,000 images, researchers may test it on 2,000 new images.
So, if performance remains strong, the model is considered successful.
However, if performance drops significantly, improvements may be required.
Key Concepts in Supervised Learning
Before exploring algorithms, it is important to understand several core concepts.
These concepts appear repeatedly throughout machine learning.
Features
Features are the input variables used for prediction.
Therefore, they describe characteristics of the data.
For example, in a house-price prediction system:
| Feature | Example Value |
|---|---|
| House Size | 2000 sq ft |
| Bedrooms | 3 |
| Bathrooms | 2 |
| Location Score | 8 |
The model uses these features to make predictions.
Consequently, selecting relevant features can significantly improve accuracy.
Labels
Labels are the correct outputs that the model tries to predict.
Examples include:
- Spam or Not Spam
- Fraud or Legitimate
- House Price
- Disease Type
Therefore, labels act as the target values during training.
Training Data
Training data is the collection of examples used to teach the model.
Generally, larger and higher-quality datasets produce better results.
However, quantity alone is not enough.
Furthermore, the data must be accurate, representative, and properly labeled.
Loss Function
A loss function measures prediction errors.
In simple terms, it tells the model how wrong it is.
If the model predicts a house price of $300,000 but the actual price is $350,000, the loss function calculates the error.
Consequently, the algorithm uses this information to improve future predictions.
The ultimate goal is to minimize the loss as much as possible.

Types of Supervised Learning
There are two primary categories of supervised learning.
Each serves a different purpose.
Classification
Classification predicts categories or classes.
Instead of predicting numerical values, it predicts labels.
Examples include:
- Spam detection
- Disease diagnosis
- Sentiment analysis
- Face recognition
For instance, an email is classified as either:
- Spam
- Not Spam
Therefore, classification focuses on assigning categories.
Read More: Types of Supervised Learning Algorithms
Regression
Regression predicts continuous numerical values.
Instead of categories, it estimates quantities.
Examples include:
- House prices
- Stock values
- Temperature forecasting
- Sales predictions
For example, a model might predict:
- House Price = $275,000
Consequently, regression is useful whenever the output is a number.
Regression vs Classification
| Feature | Regression | Classification |
|---|---|---|
| Output Type | Continuous value | Category or class |
| Example | House price prediction | Spam detection |
| Goal | Predict numbers | Predict labels |
| Evaluation | Error measurement | Accuracy measurement |
| Common Use Cases | Forecasting, valuation | Recognition, categorization |
Popular Supervised Learning Algorithms
Many algorithms fall under the supervised learning category.
Some are simple and beginner-friendly, while others are highly advanced.
The table below summarizes several popular algorithms.
| Algorithm | Type | Best Use Case | Difficulty Level |
|---|---|---|---|
| Linear Regression | Regression | Price prediction | Beginner |
| Logistic Regression | Classification | Binary classification | Beginner |
| Decision Tree | Both | Easy-to-explain predictions | Beginner |
| Random Forest | Both | High accuracy tasks | Intermediate |
| Support Vector Machine (SVM) | Classification | Complex classification | Intermediate |
| K-Nearest Neighbors (KNN) | Classification | Pattern recognition | Beginner |
| Neural Networks | Both | Deep learning applications | Advanced |
Linear Regression
Linear Regression predicts continuous values.
For example, it can estimate housing prices based on location, size, and number of rooms.
Therefore, it is often the first algorithm beginners learn.
Logistic Regression
Despite its name, Logistic Regression is primarily used for classification.
It predicts probabilities and assigns categories accordingly.
As a result, it is commonly used for spam detection and customer churn prediction.
Decision Trees
Decision Trees make predictions through a series of logical decisions.
So, they are easy to visualize and interpret.
Consequently, many businesses use them when transparency is important.
Read More: 10 Most Popular Supervised Learning Algorithms In Machine Learning
Random Forest
Random Forest combines multiple decision trees.
Because it uses many trees instead of one, accuracy often improves.
Furthermore, it reduces the risk of overfitting compared to a single decision tree.

Real-World Applications of Supervised Learning
Supervised learning powers many technologies people interact with daily.
In fact, some of the world’s largest technology companies rely heavily on it.
The following examples demonstrate how supervised learning creates value in the real world.
Amazon Product Recommendations
When customers browse products, Amazon analyzes their behavior, purchases, and interests.
Consequently, the platform predicts which products users are most likely to buy next.
These recommendations improve customer experience while increasing sales.
Tesla Object Detection
Tesla’s autonomous driving systems rely on supervised learning models trained on massive datasets.
These models identify:
- Pedestrians
- Traffic lights
- Vehicles
- Road signs
As a result, the vehicle can better understand its environment and make safer driving decisions.
Read More: Optimus (robot)
Meta Spam Filtering
Meta uses supervised learning to identify spam content across its platforms.
The system learns from millions of previously labeled messages.
Consequently, harmful or unwanted content can be detected and filtered automatically.
Benefits and Limitations of Supervised Learning
Supervised Learning has become one of the most widely used machine learning techniques in the world. Today, businesses, researchers, and technology companies rely on it to solve a wide range of problems. As a result, it plays a major role in modern artificial intelligence systems.
However, like any technology, supervised learning is not perfect. While it offers several advantages, it also comes with certain challenges. Therefore, understanding both sides is important before applying it to real-world projects.
Benefits of Supervised Learning
High Prediction Accuracy
One of the biggest advantages of supervised learning is its ability to make accurate predictions. Because the model learns from labeled examples, it can identify patterns and relationships within the data.
Furthermore, prediction accuracy often improves when large amounts of high-quality training data are available. As a result, supervised learning is widely used in applications where reliability is essential.
Easy Performance Evaluation
Another major benefit is that model performance is relatively easy to measure. Since the correct answers are already known, developers can compare predictions with actual outcomes.
Therefore, evaluating accuracy becomes much more straightforward. In addition, performance metrics help identify areas that need improvement.
Supports a Wide Range of Applications
Supervised learning can solve both classification and regression problems. Because of this, it can be applied across many industries and use cases.
For example:
- Healthcare uses it for disease prediction.
- Finance uses it for fraud detection.
- Retail uses it for product recommendations.
- Education uses it to analyze student performance.
Moreover, new applications continue to emerge as machine learning technology advances.
Improves Over Time
Machine learning models can be retrained whenever new data becomes available. As a result, they can adapt to changing conditions and improve their performance.
Likewise, organizations can continuously refine their systems to achieve better outcomes. Ultimately, this ability to learn from new information makes supervised learning highly valuable.
Read More: Benefits of Supervised Learning
Limitations of Supervised Learning
Although supervised learning offers many benefits, it also has several limitations.
Requires Large Amounts of Labeled Data
Perhaps the biggest challenge is obtaining labeled data. Unlike raw data, labeled datasets require human effort to create and verify.
Consequently, data preparation can become expensive and time-consuming. In many cases, organizations spend more time preparing data than building the actual model.
Data Quality Directly Impacts Results
The quality of the dataset significantly affects model performance. If the training data contains errors, missing values, or incorrect labels, the model may learn the wrong patterns.
Therefore, high-quality data is essential for achieving reliable predictions. Indeed, even advanced algorithms struggle when trained on poor datasets.
Risk of Overfitting
Another common challenge is overfitting. This happens when a model memorizes training examples instead of learning general patterns.
As a result, the model may perform exceptionally well during training but poorly on new data. For this reason, preventing overfitting is a critical part of machine learning development.
Difficulty Handling Completely New Situations
Supervised learning models learn from historical examples. However, they may struggle when faced with situations that are very different from the data they were trained on.
In contrast, human beings can often apply reasoning to unfamiliar scenarios. Machine learning models, on the other hand, depend heavily on the information available during training.

Benefits vs. Limitations Table
| Benefits | Limitations |
|---|---|
| High prediction accuracy | Requires labeled data |
| Easy performance evaluation | Data labeling can be expensive |
| Supports many business applications | Sensitive to poor-quality data |
| Can improve with additional training data | Risk of overfitting |
| Suitable for classification and regression | Limited by training examples |
| Enables automation and scalability | May require significant computational resources |
Supervised Learning vs. Unsupervised Learning
Many beginners encounter both supervised learning and unsupervised learning early in their machine learning journey. Although the two approaches belong to the same field, they solve problems in very different ways.
Therefore, the primary difference lies in the data.
Supervised learning uses labeled datasets that contain correct answers. In contrast, unsupervised learning works with unlabeled data and attempts to discover hidden patterns on its own.
For example, a supervised learning model may learn to identify spam emails from labeled examples. Meanwhile, an unsupervised learning model might group customers into different segments without being told what those groups should be.
Therefore, supervised learning focuses on prediction, while unsupervised learning focuses on exploration and pattern discovery.
Read More: Supervised vs. Unsupervised Learning
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Type | Labeled Data | Unlabeled Data |
| Goal | Predict outcomes | Discover patterns |
| Training Guidance | Yes | No |
| Output | Predictions | Groups and clusters |
| Examples | Spam detection, price prediction | Customer segmentation, anomaly detection |
As a result, supervised learning is often easier for beginners to understand because the model learns from clearly defined examples.
Common Mistakes in Supervised Learning
Even experienced practitioners occasionally make mistakes. Nevertheless, beginners are especially vulnerable to a few common issues. For this reason, understanding these problems early can save significant time, effort, and resources.
Overfitting
Overfitting occurs when a model learns the training data too well. Instead of capturing general patterns, it memorizes specific examples.
As a result, the model performs extremely well on training data. However, it performs poorly on new, unseen data. In other words, it fails to generalize effectively.
Signs of Overfitting
- Extremely high training accuracy
- Low testing accuracy
- Weak real-world performance
How to Reduce Overfitting
- Use more training data
- Simplify the model
- Apply regularization techniques
- Use cross-validation
Moreover, these techniques encourage the model to learn broader patterns. Ultimately, this improves performance on unseen data.
Underfitting
Underfitting represents the opposite problem. In this case, the model is too simple to capture important relationships in the data.
Therefore, it performs poorly on both training and testing datasets. Additionally, it fails to understand the problem’s underlying structure.
Common causes include:
- Insufficient training time
- Poor feature selection
- Overly simple algorithms
From another perspective, underfitting often indicates that the model lacks enough complexity to learn effectively.
Poor-Quality Data
A machine learning model is only as strong as the data it learns from. If the dataset contains missing values, errors, or incorrect labels, performance will degrade significantly.
Consequently, even highly advanced algorithms can generate unreliable predictions. Indeed, poor data quality is one of the leading causes of machine learning failure.
Examples of Poor Data
- Missing customer records
- Incorrect labels
- Duplicate entries
- Outdated information
Therefore, ensuring data quality is not optional—it is essential.
Data Leakage
Data leakage happens when information from the testing dataset accidentally enters the training process.
At first glance, the model may appear highly accurate. However, this performance is misleading.
Once deployed in real-world environments, the model usually performs poorly. Because of this, data leakage is considered a serious problem in machine learning workflows.
For this reason, training and testing datasets must always remain strictly separated.
Best Practices for Supervised Learning
Applying best practices can significantly improve model performance. In addition, these methods help reduce errors and improve reliability across different scenarios.
Choose the Right Dataset
The dataset forms the foundation of every supervised learning project. Therefore, selecting the right dataset is a critical first step.
A strong dataset should be:
- Accurate
- Relevant
- Representative
- Properly labeled
- Up-to-date
As a result, the model is more likely to learn meaningful and reliable patterns.
Clean the Data
Raw data is rarely perfect. Consequently, data cleaning becomes an essential step before training begins.
Common cleaning tasks include:
- Removing duplicates
- Fixing errors
- Handling missing values
- Standardizing formats
Furthermore, clean data improves stability and enhances model accuracy. In fact, better data often leads to better models.
Select Useful Features
Not all features contribute equally to prediction accuracy. In fact, some features may even reduce performance by adding noise.
Therefore, feature selection plays a key role in improving efficiency and accuracy.
For example, when predicting house prices:
Useful features:
- House size
- Number of bedrooms
- Location
Less useful features:
- Random ID numbers
- Irrelevant text fields
So, the model focuses only on meaningful information.
Split Data Properly
A standard machine learning workflow divides data into different sets:
| Dataset Type | Purpose |
|---|---|
| Training Set | Learn patterns |
| Validation Set | Tune model |
| Testing Set | Evaluate performance |
This separation ensures fair evaluation and reduces bias.
Thus, developers gain a more realistic understanding of model behavior in real-world scenarios.
Continuously Monitor Performance
Machine learning models do not remain static after deployment. Over time, real-world data evolves.
As a result, model performance may gradually decline. Meanwhile, new patterns may appear that were not present during training.
In addition, environmental and user behavior changes can also affect accuracy.
For this reason, continuous monitoring and periodic retraining are essential for long-term success.
Future Trends in Supervised Learning
The field of supervised learning is evolving rapidly. Moreover, advancements in artificial intelligence are unlocking new possibilities across industries.
Integration with Large Language Models
Large Language Models (LLMs) have transformed modern AI systems. Many of these models depend heavily on supervised learning during training.
Consequently, supervised learning remains a foundational element of modern AI architectures.
Examples include:
- Chatbots
- Virtual assistants
- Content generation tools
- Language translation systems
Therefore, supervised learning continues to drive innovation in AI development.
Better Data Labeling Techniques
Traditionally, data labeling has been expensive and time-consuming. However, modern tools are improving this process significantly.
As a result, organizations can now build training datasets more efficiently than before.
In addition, automation reduces human effort while maintaining quality.
Read More: Best Practices for Data Labeling
Human-in-the-Loop Learning
Human expertise is increasingly integrated into machine learning workflows. Instead of replacing humans, AI systems now collaborate with them.
Consequently, model accuracy and reliability improve significantly. Moreover, this collaboration reduces errors in critical applications.
Hybrid Learning Approaches
Researchers are combining supervised learning with other machine learning paradigms.
For example:
- Combination of Supervised and Unsupervised Learning
- Supervised + Reinforcement Learning
- Supervised + Deep Learning
Therefore, future systems are expected to become more flexible, adaptive, and powerful.
Conclusion
Supervised Learning is one of the most important pillars of machine learning and serves as the foundation for many modern AI systems.
Throughout this guide, we explored how supervised learning uses labeled data, input-output pairs, and structured training examples to help machines make predictions. Furthermore, we examined essential concepts such as features, labels, loss functions, classification, and regression.
In addition, we explored real-world applications in companies like Amazon, Tesla, and Meta. Moreover, we discussed algorithms, benefits, limitations, common mistakes, and best practices in detail.
As artificial intelligence continues to evolve, supervised learning will remain a core technology powering intelligent systems worldwide.
Therefore, if you are starting your machine learning journey, mastering supervised learning is a crucial first step.
Moreover, it is highly recommended to explore Unsupervised Learning to understand how machines discover hidden patterns without labeled data. Together, these approaches form the backbone of modern machine learning.
Frequently Asked Questions (FAQs)
1. What is Supervised Learning in simple words?
Supervised Learning is a machine learning approach where a system learns from examples that already contain correct answers.
2. Why is it called Supervised Learning?
It is called “supervised” because the model learns under guidance using labeled data.
3. What is labeled data?
Labeled data includes both input features and their correct outputs.
4. What are the main types of Supervised Learning?
The two main types are classification and regression.
5. What is the difference between classification and regression?
Classification predicts categories, while regression predicts continuous values.
6. Which industries use Supervised Learning?
Industries such as healthcare, finance, retail, education, and transportation widely use supervised learning.
7. What is overfitting?
Overfitting occurs when a model memorizes training data instead of learning general patterns.
8. Why is data quality important?
Because poor-quality data leads to inaccurate and unreliable predictions.
9. Can Supervised Learning work without labeled data?
No, it requires labeled data for training.
10. Is Supervised Learning used in Large Language Models?
Yes, many LLMs use supervised learning during key training stages.

Key Takeaways
- Supervised Learning relies on labeled data for prediction.
- It is widely used across industries and applications.
- Classification and regression are its core categories.
- Data quality strongly affects performance.
- Overfitting and data issues are common challenges.
- Modern AI systems still depend heavily on supervised learning.
- It forms the foundation for advanced machine learning topics.
Read More: Unlock Massive Traffic With This SEO Roadmap Strategy
Call To Action
Need SEO content that ranks on Google and keeps readers engaged?
I create:
- SEO blog posts
- Keyword-focused articles
- Human-style content
- Easy-to-read blogs
- High-engagement website content
Let’s build content that performs.
📧 Email: craziya167@gmail.com
Author Bio
Digital Raziya is an SEO content writer specializing in AI, machine learning, and digital marketing.
She creates simple and clear content that is easy to read. In addition, she focuses on SEO-optimized articles that help websites grow. She is an expert in on-page SEO. Overall, her goal is to make complex topics easy for everyone.